
Building a 3D Model of the World from Internet Photos
For 17 years, the math only worked on famous landmarks. Last month, a Cornell lab cracked the long tail.

Today, you can be geolocated from a single photo you posted online. Reflections in your sunglasses. The angle of the sunlight. The slice of a building outside the window.
But what if you took every photo that’s been uploaded in a given area and fused it all together? Every Instagram post. Every Snapchat story. Every WhatsApp share. Every random tourist shot on Flickr. Stack them all into a 3D model of the place. A real god’s eye view, built out of everyone’s vacation photos.
For 17 years, the answer was: kind of -- but only for the places everyone already photographs. The Eiffel Tower? Easy. The Coliseum? Done. Your neighborhood? Not a chance. There just weren’t enough photos.
Last month, that wall came down.
Watch the full video here:
YouTube only gives you so many minutes, though, and this rabbit hole runs deeper than I could fit in 15. So let’s get into it.
The 18-year arc
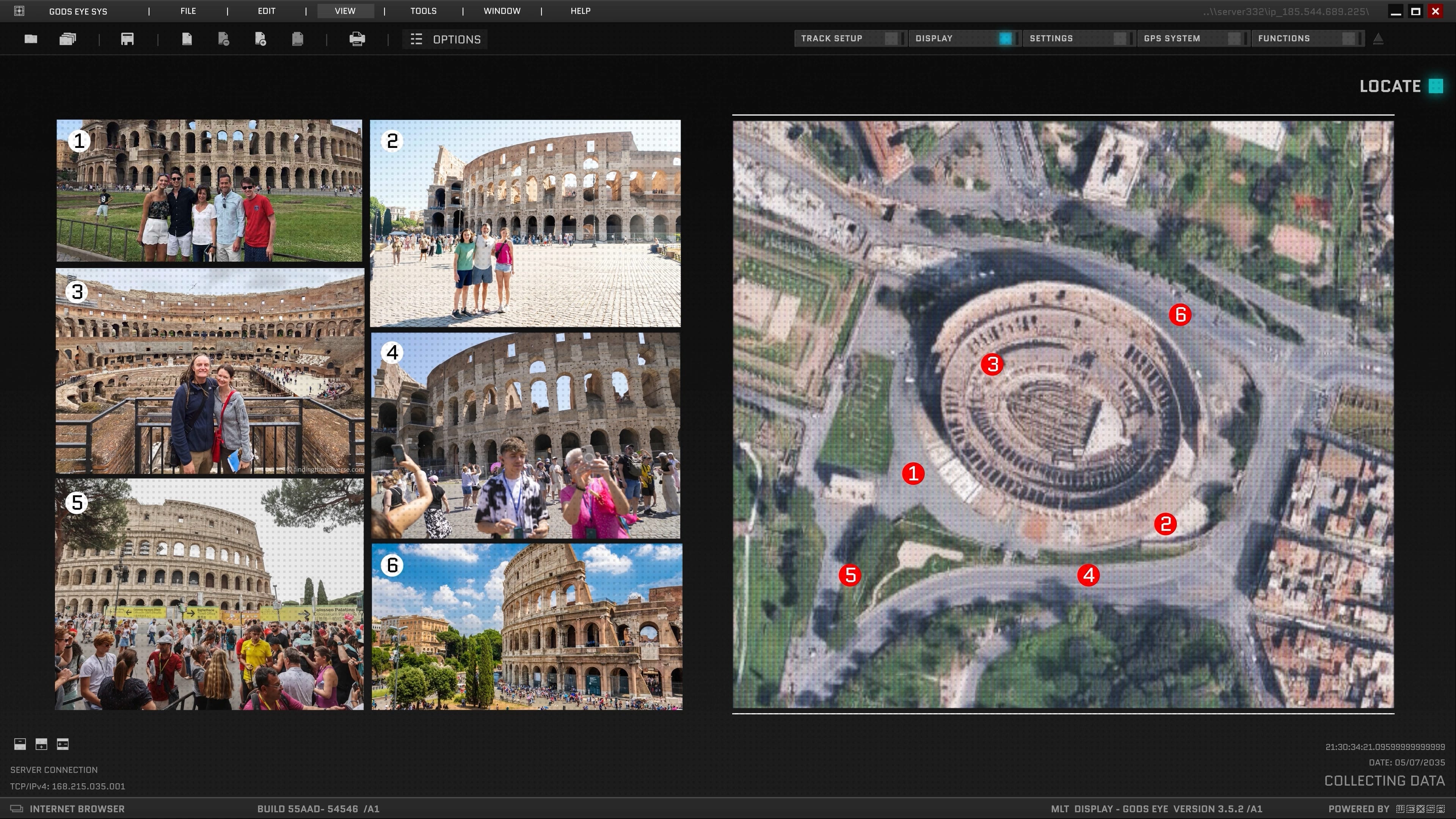
In 2008, a UW PhD student named Noah Snavely defended a dissertation titled Scene Reconstruction and Visualization from Internet Photo Collections. The premise of that thesis -- written 18 years ago -- is the premise of the paper I want to walk you through today.
The first time it got famous was the year after. A team at the University of Washington led by Sameer Agarwal, with Snavely as second author, downloaded thousands of tourist photos of Rome off Flickr and ran them through a technique called Structure-from-Motion -- basically reverse-engineering where every camera had been standing when it took its photo. Then they stitched the images into a single coherent 3D model of the city. They called it Building Rome in a Day. A day being how long the processing took on what was, at the time, a pretty heroic compute setup.

That paper didn’t just give you a 3D Coliseum. The techniques it introduced -- skeletal sets, bundle adjustment at scale, posing photos against a global 3D model -- rippled outward into the whole field. It’s the toolkit Street View-style systems are still built on today. A bunch of those folks ended up at Google. So did I -- I worked on photogrammetry over on the Maps team alongside some of them.
For the next nine years, the field scaled this approach hard. By 2015, a UNC team had reconstructed the entire planet from Flickr in six days. Same technique, planetary scale.
The Long Tail
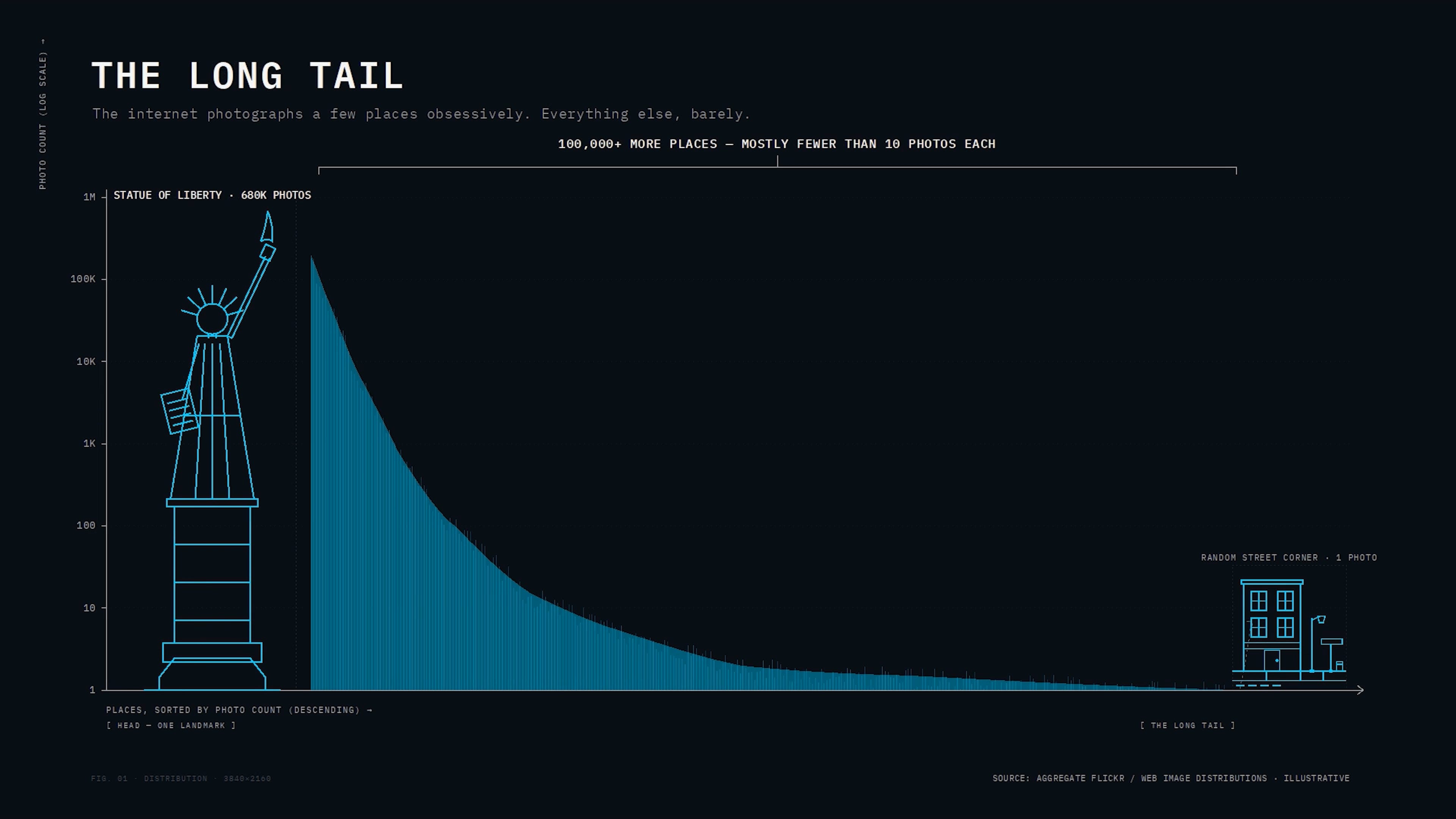
Despite all of that, the technique only really worked on the head. The long tail just sat there.
Photos on the internet aren’t evenly distributed. There’s a small head -- the most famous landmarks, where you have millions of shots from every angle. Then there’s the torso. And then there’s the long tail: that local coastal fort. That random monument in your hometown. Your neighborhood. A handful of photos, if any.
The methods that worked beautifully on the head produced hollow shells everywhere else. The internet just didn’t have enough photos for the math to work. Which is why Google goes through the elaborate, expensive effort of flying airplanes, driving Street View cars, and buying satellite imagery. They can’t get the world’s photos to do the job for them.
That was the wall the field would spend the next decade banging its head against.
A decade of chipping at the wall

The field tried everything.
2018 -- MegaDepth. Snavely’s Cornell PhD student Zhengqi Li flipped the question. Instead of using internet photos to build 3D scenes, use the 3D scenes you already have to train a neural network. Teach it to predict depth from any single new photo. Per-pixel depth maps out of any tourist shot.

2019 -- Mannequin Challenge. Google Research pulled a stunt I still think about. They scraped 2,000 of those 2016 mannequin-challenge videos off YouTube -- the meme where everyone freezes in place and one person walks around with a phone. Because the people are static and the camera moves, every video is a free Structure-from-Motion problem, conveniently with humans embedded in it. They trained a depth network that worked on moving people -- something prior methods had largely assumed away. Which makes me wonder. Every TikTok trend. Every Instagram challenge. Every viral pose-and-hold thing. How many of those are quietly data collection plays for ML labs

2021 -- NeRF in the Wild. A Google Research team takes Neural Radiance Fields and adapts the architecture for the messy reality of internet photos. The killer demo: over 1,300 photos of the Brandenburg Gate, taken across years, in different lighting, with random tourists in every frame. The model disentangles the geometry from the lighting. So you can change the time of day on the same building. Same model. Pretty freaking clever.
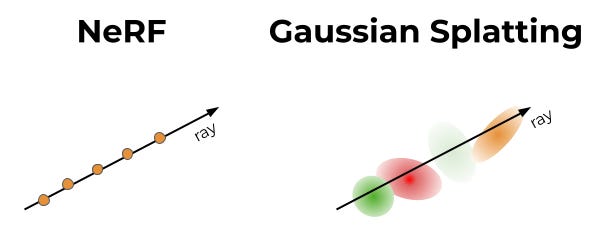
2023 -- 3D Gaussian Splatting. Inria swaps the implicit neural network for millions of explicit, fuzzy ellipsoids. Same image quality, roughly 100x faster to render. Real-time fly-throughs in a browser.

2024 -- Wild Gaussians. The in-the-wild trick, this time on the new substrate. Interactive sliders that drag a landmark from sunrise to sunset to night in real time. Now running in a browser tab, not on a render farm.

2024 -- MegaScenes. Snavely’s lab teams up with Stanford and Adobe to build a dataset. 430,000 scenes. Two million images. 100,000 Structure-from-Motion reconstructions. All scraped from Wikimedia Commons, organized by what they’re photos of. Globally. The infrastructure for everything that comes next.

2025 -- Doppelgangers++. If you try to reconstruct something like the Belvedere Palace in Vienna, your software keeps folding the building in half. Why? The front and back look identical in pixel space. Bilateral symmetry. Same problem with cathedrals, capitols, anything with repeated facades. The field calls these “doppelgangers.” Snavely’s team trains a transformer to detect them. Their project page has this beautiful interactive viewer where you can fly around a monument and see exactly which photos contributed to the reconstruction -- each camera frustum lit up around the building like a swarm. Hundreds of strangers’ vacation photos, stitched into one coherent 3D model.

2025 -- VGGT. A parallel thread on the geometry side kills per-scene optimization entirely. Oxford VGG and Meta publish a feed-forward transformer that takes any pile of photos and predicts cameras and geometry in a single pass. In seconds. No more fragile pipelines. It wins Best Paper at CVPR 2025 out of more than 13,000 submissions.

2025 -- π³ (”pi cubed”). A sister architecture that fixes VGGT’s main weakness. VGGT secretly picks one photo as the “reference” and predicts everything relative to it -- so if you have a bad anchor photo, you get a broken reconstruction. π³ throws the anchor out entirely.
Hold those last two names in your head. They’re load-bearing for what comes next.
The chicken-and-egg problem
By early 2026, the field had foundation models. It had a dataset. It had Gaussians and NeRFs and rendering tricks for every occasion. What it still didn’t have was a way to train any of these models on the long tail of the world. You can’t train a model to reconstruct what nothing else can reconstruct. No ground truth, no training data, no answers. Stuck.
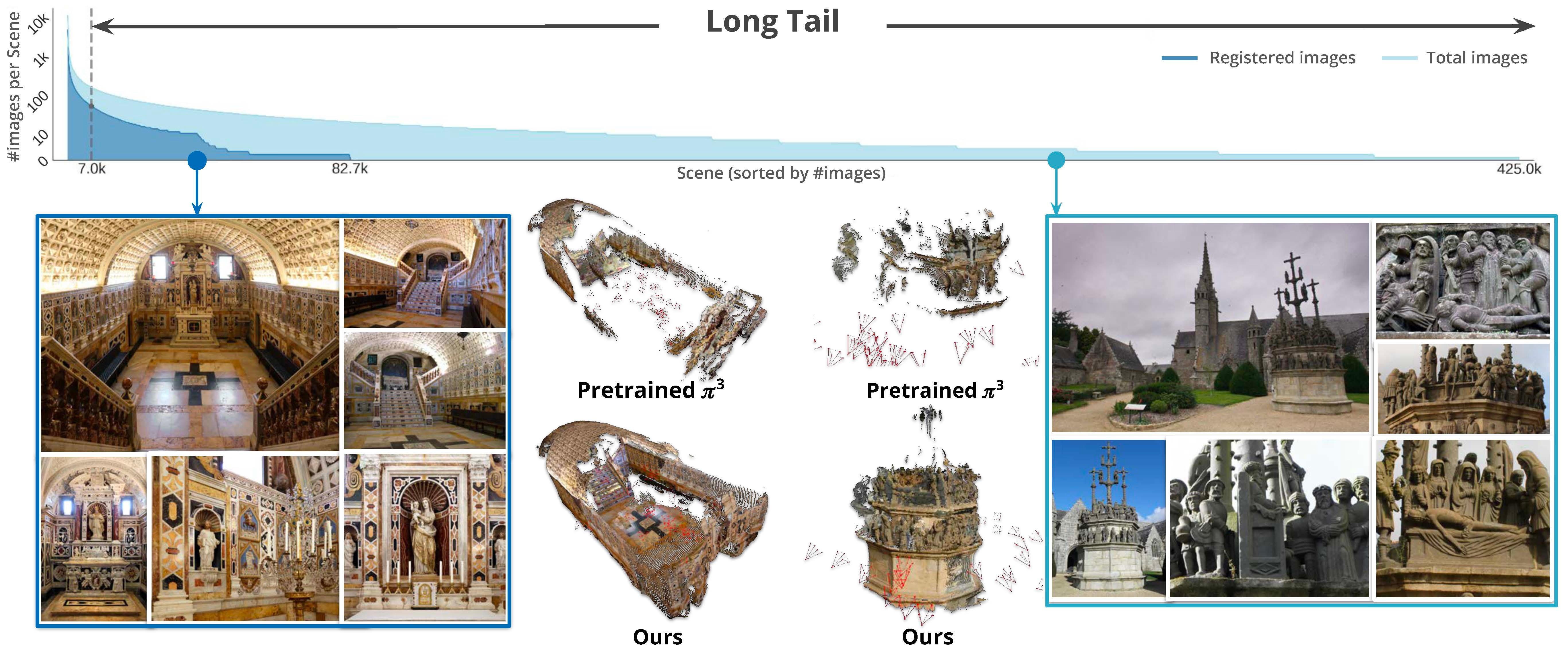
MegaDepth-X -- same Cornell lab, another Snavely PhD student named Yuan Li -- solved it with a trick that’s almost embarrassing in hindsight.
Take the well-photographed famous landmarks where ground truth does exist. Throw away most of the photos on purpose. Simulate what the messy long tail looks like. Train the model on the harder version with the answer key borrowed from the dense version. Sparring with a weighted vest. The real game feels easier.
Then fine-tune VGGT and π³ on the new data. Two parallel experiments. Both improve dramatically. Same architectures, just trained on the long tail of the world. The contribution lifts both leading foundation models, which proves the data is real -- not a one-architecture fluke.
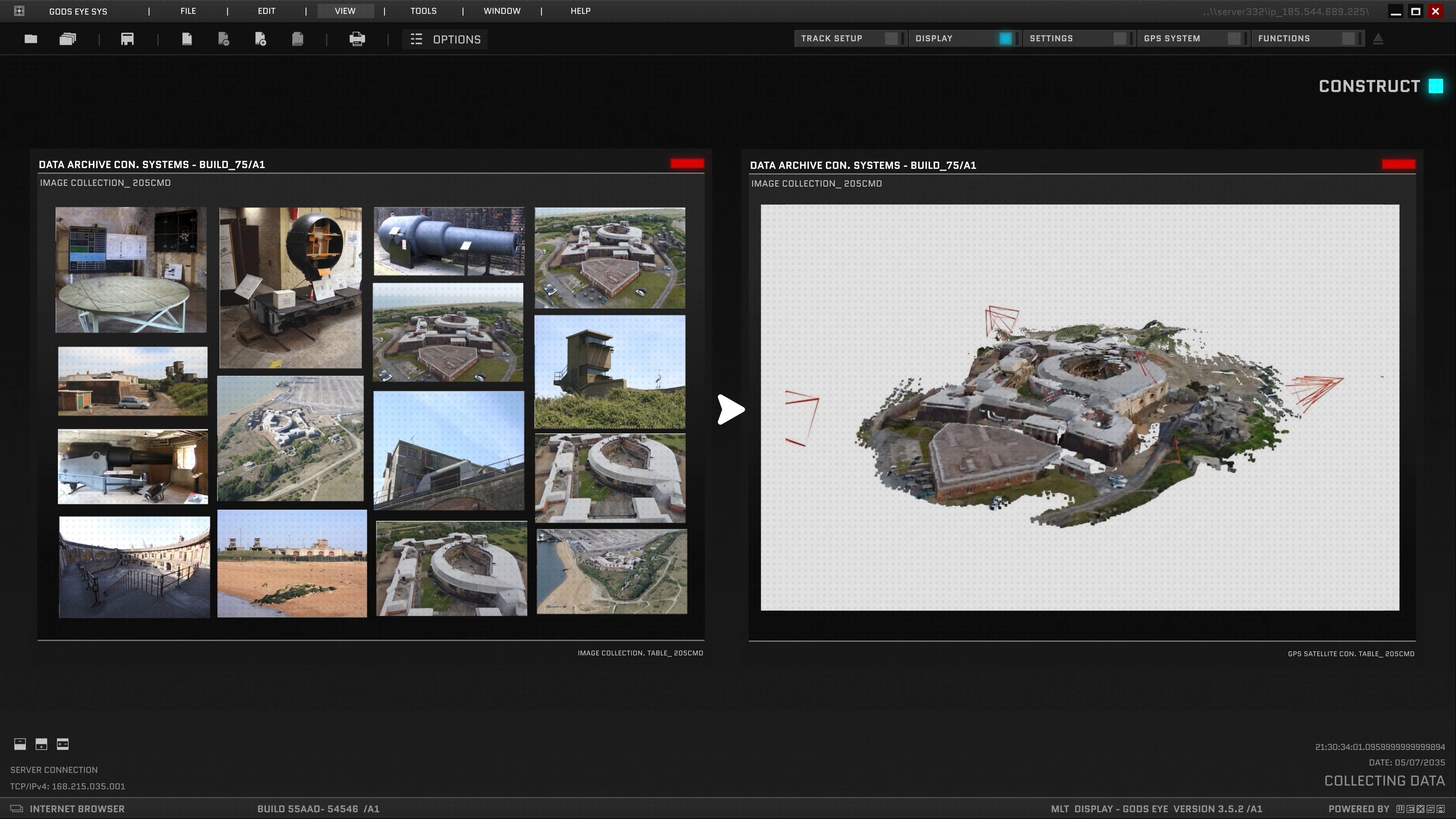
On the hardest sparse scenes, off-the-shelf π³ hits about 75% rotation accuracy. After fine-tuning on MegaDepth-X, it climbs to 86%. The wall the field had been hitting since 2015 just got punched through. Which means: random photos of basically anywhere on Earth can now be turned into a coherent 3D model.
The arc that started in 2008 with Snavely’s UW dissertation just closed. Eighteen years later.
Why an intelligence agency cares about your vacation photos
Here’s where it gets interesting.
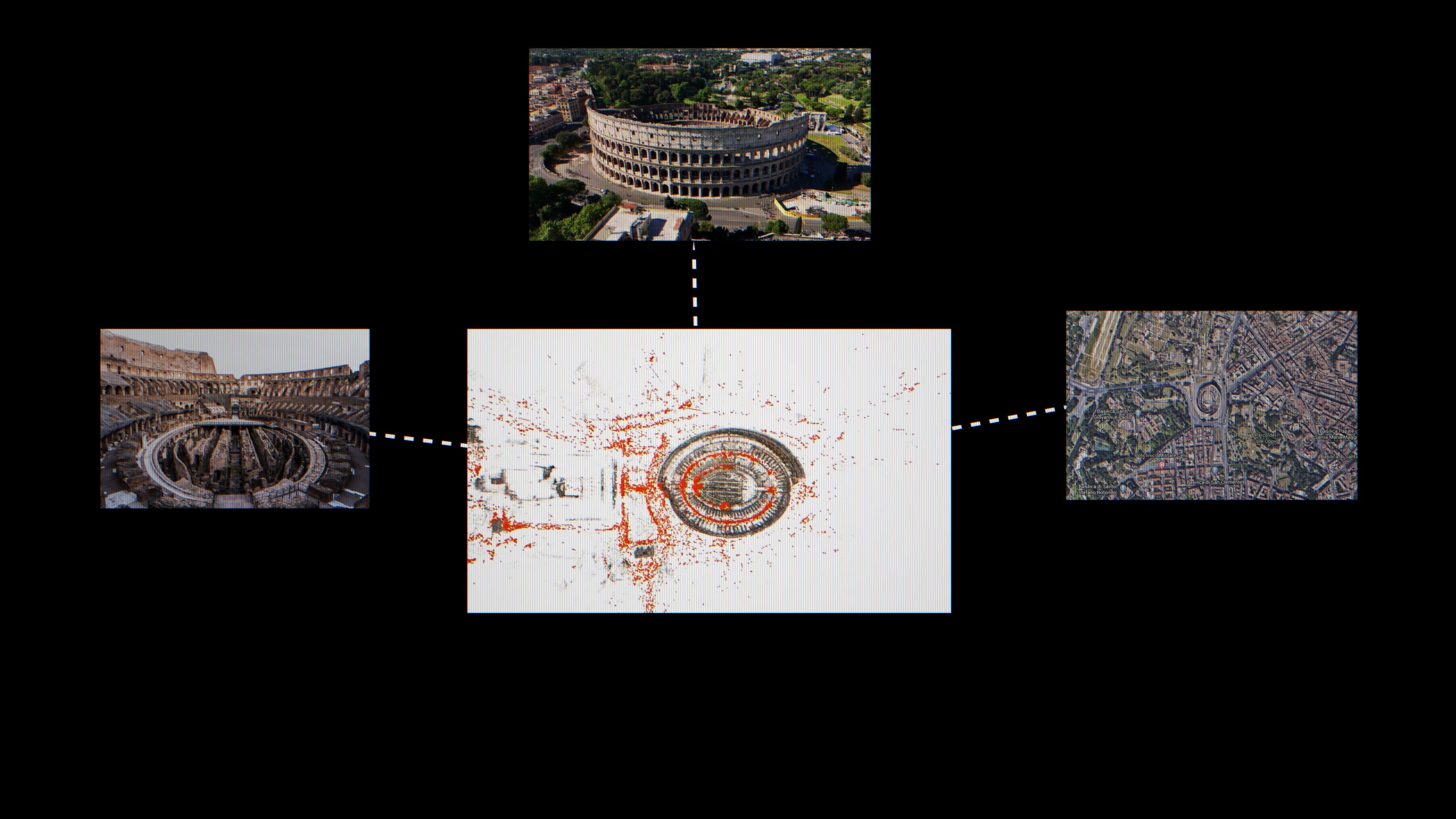
A while back, I covered SkyFall-GS. The setup: Google’s whole map of the world relies on flying mapping planes, driving Street View cars, and buying satellite imagery -- but they can’t fly mapping planes everywhere. Plenty of governments don’t let foreign aircraft loiter overhead with cameras pointed down. Dubai, for example. So you’re stuck with whatever the satellites give you, which is sparse and low-resolution. SkyFall-GS uses 3D Gaussian Splatting plus image-diffusion priors to fill those gaps from above -- the model hallucinates plausible geometry where the data runs out.
Turns out there’s a ground-level equivalent. Last April, SRI International dropped a paper called Diffusion-Guided Gaussian Splatting. Same idea, opposite direction of attack. Take ground-level photos. Drone shots. Satellite data. Fuse all of it into one 3D model. Let the diffusion model fill the gaps wherever any single source runs out.

Why does SRI care? Because they’re a contractor for the Intelligence Advanced Research Projects Activity (IARPA) -- the intelligence community’s equivalent of DARPA -- and a program called Walk-through Rendering from Images of Varying Altitude (WRIVA). The intelligence community loves their acronyms. WRIVA has been running for 42 months since 2023, across 34 institutions, with test-and-evaluation by Johns Hopkins APL and MITRE. All of them trying to do exactly this. Build photorealistic 3D walk-throughs of places agents can’t physically go.
Refugee camps. Hard-target sites. Closed cities. Places you need to know before you arrive.
And it’s not just the U.S. MegaDepth-X itself was funded in part by Korea’s National AI Research Lab Project. Same race. Different country footing the bill.

This is the pattern with every spatial-intelligence story I cover. The same tech shows up in a Cornell research paper, a Netflix VFX tool (Vista4D dropped last month), and an intelligence program. Usually within months of each other. These use cases for mapping and understanding the world always have commercial and military applications. They always have. They always will. Don’t forget that.
The 4D frontier

There’s still a piece missing. The world isn’t static. It’s 4D. People move in it. Time passes. Everything I’ve described so far is buildings and monuments standing still.
Researchers are now doing the same trick for casual handheld video. Papers like MoSca and Shape of Motion pull 4D out of a single phone clip -- not just the geometry of the scene, but the motion of the things inside it.
We’re nowhere near fusing every concertgoer’s iPhone into a free-viewpoint replay of a Taylor Swift show. Yet. But you can see where this is going.
The sensorium has come to life

Step back for a second.
We capture photos constantly. Every iPhone. Every dashcam. Every photo posted online on whichever platform you care about. And now we have the means to figure out not just where each one of those photos was taken, but to extract the 3D structure of the world from any of them.
Put it all together, and the sensorium has come to life. A real god’s eye view, built from everyone’s vacation photos and status updates, fused. The photos have been uploading themselves into the open for years. The thing nobody could do until last month was pull them all back together. That just changed. What gets done with this is still to be seen.
If you want the rendering-side companion -- 4D Gaussian Splatting from purpose-built capture rigs, not user photos -- I’ve got two videos that cover the entertainment and sports applications of this same lineage on the channel.
If this gave you something to think about, share it with someone who should see it. The internet you’ve been uploading to is quietly becoming the map of the world.
-Bilawal
Amazing overview of the state of the art. I wish all survey papers were so well written. Thanks !
Awesome Article. Thanks great inspiring read.