
Gaussian Splatting the World with Satellite 3D & Google's One-Two Punch
This AI paper just solved Google Earth and Microsoft Flight Simulator's biggest problem. Plus, Nano Banana Pro and Gemini 3 Pro.

To say it has been quite a week is an understatement. In this edition, I want to focus on a quiet research innovation that is poised to change how we explore the world, and of course, the elephant in the room: Gemini 3 Pro and Nano Banana Pro.
How do you recreate the whole world in 3D without needing to fly planes everywhere?
This paper didn’t get a ton of attention, but it’s the closest thing I’ve seen to solving a fundamental constraint that’s limited 3D mapping for decades. Researchers have essentially cracked the problem of creating detailed city-scale 3D from satellite imagery alone, no planes, no drones, no street-level photos, just AI filling in what physics makes invisible from space.

Skyfall-GS creates navigable 3D cities from satellite imagery alone
Combining 3d gaussian splatting with the world knowledge of diffusion models.
In the full video breakdown below, you’ll see exactly what makes this a paradigm shift. Their trick is honestly kind of beautiful. They train gaussian splats on satellite views, but as it descends toward ground level, the renders turn to absolute garbage - artifacts everywhere.
Instead of fighting this, Skyfall-GS just treats those nightmare renders as the input to a diffusion model. Basically - “hey FLUX, fix this mess.” It’s like neural scene completion but actually practical, and it unlocks basically the entire world.
The nuances for getting multi-view consistency are a little more complicated than that, so watch the full video to see the full breakdown:
Implications of Skyfall-GS:
If you look at the latest computer vision research on matching features between satellite and ground-level imagery, you can imagine what the next step is — go top down AND bottom up. The applications for public and private sectors are obvious. Conflict zones, restricted airspace, aerial-denied regions, suddenly, everything becomes mappable.
Beyond Google Earth and Microsoft Flight Simulator — U.S. Army has a massive one-world terrain program that would benefit tremendously from this approach. All covered in my YouTube video.
Google’s triumphant return as the king of AI 🔭
It is perhaps no understatement to say that this has been Google’s week — with the AI behemoth dropping a one-two punch between their state-of-the-art multimodal reasoning model Gemini 3 Pro, and their state-of-the-art image generation and editing model Nano Banana Pro.
Check out the TL;DR on the key announcements here:

Nano Banana Pro — the new SOTA for image generation and editing.
Meanwhile, Nano Banana has fixed all the issues with the previous release. We get that crispy 2K and 4K resolution. Text generation is a first-class citizen, and you can squeeze up to 14 elements cohesively into one generation while retaining their individual identity and likeness.
In case you missed it, here’s my talk with two of the researchers behind Nano Banana. Including the deep lore of how this iconic name came to be.

But perhaps more critically…
You can finally generate your favorite celebrities — and meme lords are running wild.
Google is taking a page out of the Sora 2 playbook; IP generation is far less restrictive in Nano Banana Pro. It is perhaps the best model to generate a perfect likeness of celebrities and throw yourself into it. Case in point:




Nano Banana Pro excels at diagram generation and text rendering.
On the utilitarian side, the detailed diagram generation ability is absolutely fantastic, and great news for visual learners, presentation makers, and designers alike. Essentially, dump a bunch of context (whether it’s a long research paper or a Gemini 3 Pro response) and ask Nano Banana Pro to summarize it, as I do below. I was really impressed with how intuitive and accurate this is.
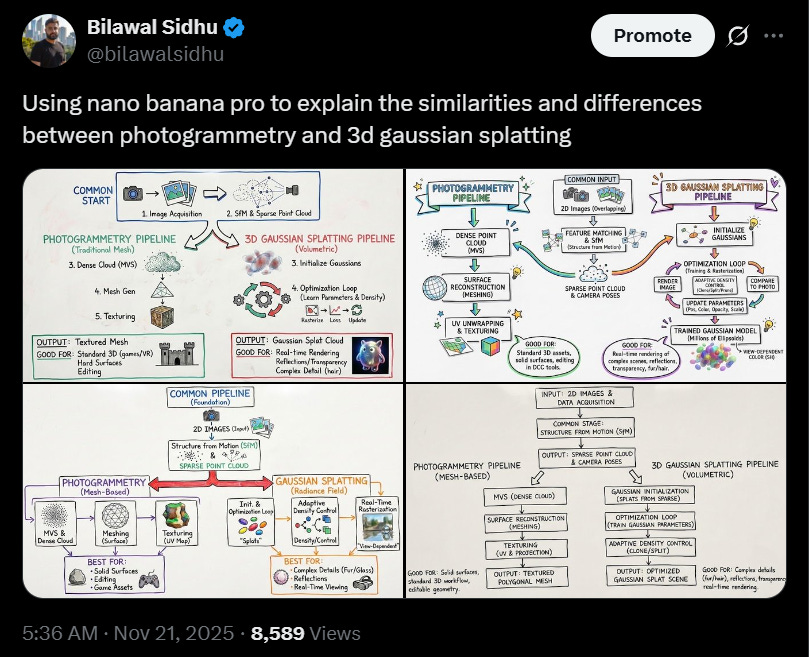
Nano Banano Pro is an expert cartographer.
While looping back to the geospatial maps theme, one experiment I tried made me realize that this model is a really good cartographer. And now with the ability to do 2K and 4K output, it’s actually high resolution enough to capture granular map features.
Check out this video experiment I did that went viral on X:

Google DeepMind’s vision for one intelligence that is multimodal in & out.
Google is flexing their full-stack approach to great effect. And after a wobbly start, it’s hard not to be impressed. In particular, the multimodal in-and-out organizing principle of the entire Gemini effort seems to be bearing fruit. Google has unlocked massive headroom on both pre-training and post-training.
While I’m not one to say I told you so, Google’s triumphant return seems obvious in hindsight, doesn’t it?

Thanks to the Google homies for early access, and stay tuned for the next edition, where I’ll be sharing my experiments and curating some of the best work being done with Gemini 3 Pro and Nano Banana Pro.
If you found this useful, share it with fellow reality mappers. The future’s too interesting to navigate alone.
Cheers,
Bilawal Sidhu
https://bilawal.ai